آموزش گام به گام اس پی اس اس به زبان فارسی
آموزش گام به گام اس پی اس اس
در این مقاله آموزشی به ادامه آموزش نرم افزار Spss در پی آموزش های قبلی این نرم افزار میپردازیم. همچنین اگر با این نرم افزار آشنایی ندارید میتوانید قبل از خواندن این مقاله به دو مقاله قبلی بروید و آنها را مطالعه کنید.
دستورهایی برای دستکاری داده ها در SPSS
در این آموزش به بررسی برخی دستورات در spss خواهیم پرداخت که برای کار با داده ها و آماده کردن آنها برای تحلیل های بعدی بسیار مهم است. به اعتقاد برخی نویسندگان در حین کار با اس پی اس اس استفاده از این دستورها بسیار کمک کننده است و بدون وجود این دستورها این نرم افزار قابل استفاده نیست.
دستور select cases
همانطور که از نام این دستور پیداست توسط آن می توان موردهایی (افرادی) خاص را انتخاب کرد. برای مثال فرض کنید می خواهیم تحلیل مورد نظر را بر روی افرادی از نمونه که دارای ویژگی خاص (برای مثال سیگاری بودن) هستند اجرا کنیم. توسط این دستور به اس پی اس اس می گوییم که تحلیل را فقط بر روی افراد سیگاری انجام بده.
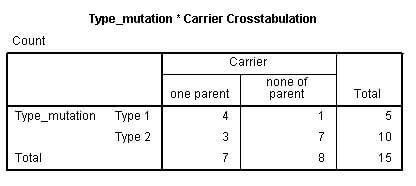
برای بررسی این دستور ابتدا فایل داده “”adl.sav را از فایل های نمونه SPSS باز کنید. می خواهیم رابطه بین فشار خون (hypertns) و ابتلا به بیماری دیابت (diabetic) را فقط در گروه مورد (Treatment) داده ها بررسی کنیم . توجه کنید که گروه مورد در متغییر group با کد ۱ مشخص شده است.
می دانیم که برای بررسی این رابطه باید از دستور Crosstabs استفاده کرد اما چون می خواهیم رابطه را فقط در گروه مورد انجام دهیم ابتدا باید دستور select cases را اجرا کنیم. برای اجرای این دستور مسیر Data>Select Cases را انتخاب کنید ویا در نوار ابزار روی دکمه عکس کلیک کنید تا کادر مکالمه مربوطه باز شود. در این کادر گزینه دوم (If condition is satisfied) را انتخاب کنید و دکمه If را کلیک کنید و متغییر group را وارد کادر سمت راست انداخته و عبارت “۱=” را تایپ کنید و گزینه continue و سپس Ok را بزنید. در این حالت در فایل داده ها فقط افراد مورد انتخاب شده اند و افراد کنترل برای آنالیزها فیلترشده اند.
حال با اجرای دستور Crosstabs رابطه بین فشار خون و دیابت را بررسی می کنیم. خروجی نرم افزار به صورت زیر است:
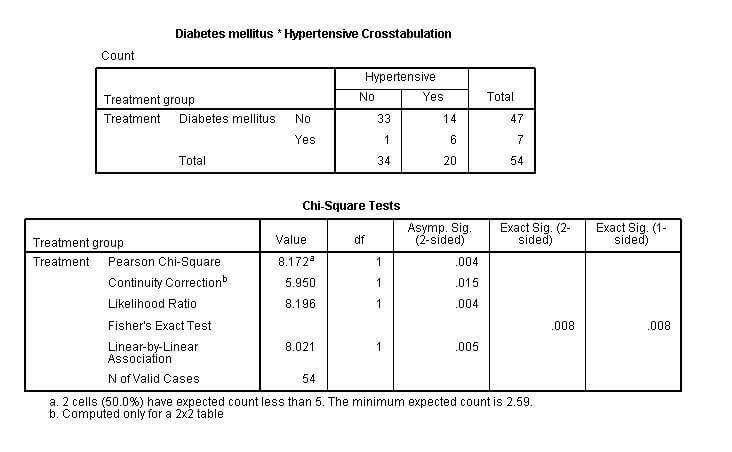
همانطور که مشاهده می کنید این همان خروجی دستور Crosstabs با این تفاوت که رابطه بین دو متغییر فشار خون و دیابت فقط در افراد “مورد” بررسی شده است.
توجه: در پنجره select cases:if که نحوه انتخاب Caseها را تعیین می کنیم گزینه های زیاد دیگری نیز برای انتخاب وجود دارد. برای مثال می توان با استفاده از صفحه کلید این کادر تعیین کنیم که برای مثال “افراد با سن کمتر یا مساوی ۷۳سال” انتخاب شوند.برای این کار باید در کادر تایپ شود : age<=30 . یا می توان از دستورهای منطقی & =(and) و| (or) استفاده کرد.
دستور split file
همانطور که از نام این دستور پیداست فایل داده هارا می شکند.به عبارتی با در نظر گرفتن یک متغیر کیفی مثل جنسیت یا مقطع تحصیلی فایل داده ها تفکیک شده و تمام آنالیزها و خروجی ها به تفکیک طبقات این متغیر کیفی ارائه خواهد شد.
برای بررسی این دستور ابتدا فایل داده۸ “adl.sav” را از فایل های نمونه SPSS باز کنید . می خواهیم رابطه بین فشارخونی بودن (hypertns) و ابتلا به بیماری دیابت (diabetic) را به تفکیک هریک از گروه های تیماری (group) بررسی کنیم.
می دانیم که برای بررسی این رابطه باید از دستور Crosstabs استفاده کرد اما چون می خواهیم رابطه را به تفکیک یک متغیر سوم بررسی کنیم ابتدا باید دستور Split file را اجرا کنیم. برای اجرای این دستور مسیر Data>Split file را انتخاب کنید و یا در نوار ابزار روی دکمه عکس کلیک کنید تا کادر مکالمه مورد نظر باز شود . در این کادر گزینه دوم (Compared groups) را انتخاب کنید و متغیر group را وارد کادر Groups Based On کنید و گزینه ok را بزنید.
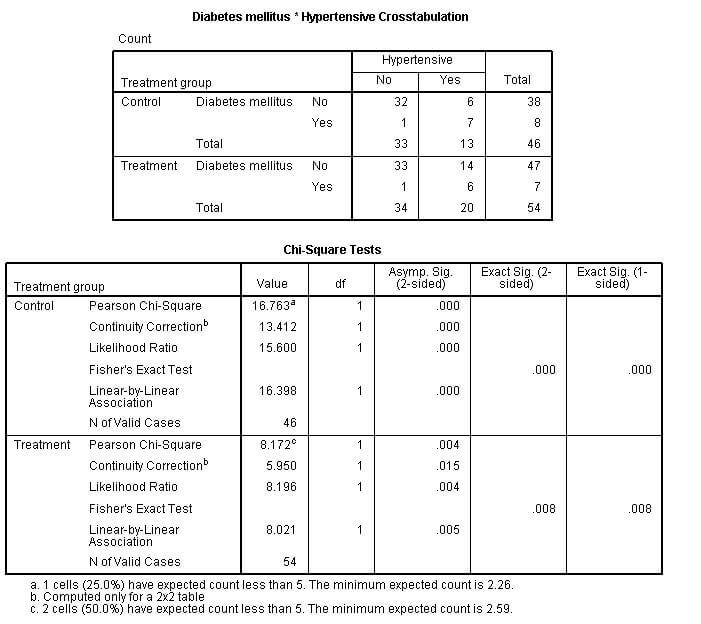
در این حالت داده ها تفکیک شده اند و حالا می توانید آنالیز مورد نظر را انجام دهید.بعد از اجرای دستور Crosstabs خروجی را به صورت زیر خواهید دید. همانطور کهد مشاهده می کنید این همان خروجی دستور Crosstabs است با این تفاوت که رابطه بین دو متغیر فشارخون و دیابت به تفکیک یک متغیر سوم بررسی شده است.
- این دستور به خصوص زمانی کاربرد دارد که بخواهیم اثر مخدوشگری یا اثرات متقابل را بررسی کنیم.
- بعد از اجرای دستور Split file فایل اس پی اس اس همواره به صورت تفکیک شده است و مادامی که فایل داده ها به این صورت است، در قسمت نوار وضعیت SPSS عبارت Split file on نوشته شده است. در صورتی که میخواهید از این حالت خارج شوید دوباره مسیر بالا را طی کنید و در کادر مکالمه ای مذکور گزینه “Analysis all cases” را انتخاب کنید و ok را کلیک کنید. در این حالت فایل از حالت تفکیکی در آمده و می توانید تمام داده ها را تحلیل کنید.
- در صورتی که گزینه “Organize output by groups” را انتخاب کنید خروجی فایل ها را به صورت تفکیکی ارائه می دهد اما ن کنار هم.
- این دستور ابتدا فایل داده ها را براساس متغیر تفکیکی مرتب می کند و سپس فایل داده ها را تفکیک می کند و از آنجایی که عموما فایل داده ها مرتب نیست همواره گزینه “Sort the file…” را انتخاب کنید.
دستور Weight Cases
زمانی که داده ها از نوع فراوانی باشند برای تعریف داده ها می توان از این دستور استفاده کرد دستور را با یک مثال توضیح میدهیم.
مثال: در یک مطالعه ژنتیکی مربوط به ساختار کروموزوم ها ۲۸ نفر برحسب نوع انحرافی که ساختار کروموزوم آنها از وضع طبیعی دارد و برحسب اینکه والدینشان حامل این انحراف هستند یا نه رده بندی شده اند و در نتیجه داده های زیر بدست آمده است:
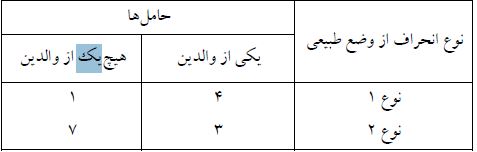
می خواهیم آزمون کنیم که “نوع انحراف از وضع طبیعی” مستقل از “حامل بودن والدین” است یا خیر.
برای انجام این آزمون قاعدتا باید ابتدا داده ها را در SPSS وارد کرد!! که البته در این قسمت تنها بر نحوه ورود داده ها بحث خواهیم کرد و نه برنحوه انجام آزمون آماری آن. برای این کار دو راه وجود دارد. راه اول این که داده ها را به طور خام وارد اس پی اس اس کنیم یعنی دو متغیر برای “نوع انحراف از وضع طبیعی” و “حامل بودن والدین” تعریف کنیم آنها را کد بندی کرده و به صورت زیر وارد کنیم :
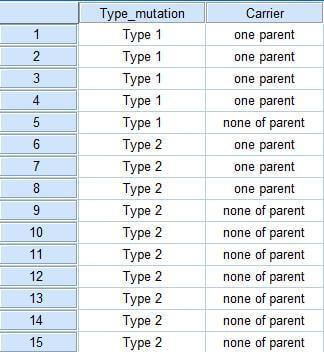
حال اگر فراوانی داده ها در هریک از خانه های جدول زیاد باشد و بخواهیم از روش اول استفاده کنیم ورود داده ها وقت زیادی خواهد گرفت. راه دوم این است که طبقات داده ها را به نرم افزار معرفی برای آنها فراوانی تعریف کنیم و به فراوانی ها وزن دهیم.
به عبارتی در این مثال که ۴طبقه (به صورت ترکیبی) داریم کافیست ۴ طبقه را به عنوان ۴ مشاهده تعریف کنیم و برای آنها فراوانی تعریف کنیم به عبارتی داده ها را به صورت زیر تعریف کنیم . توجه کنید یک متغیر Frequency برای تعریف فراوانی ها به دو متغیر قبلی اضافه شده است.
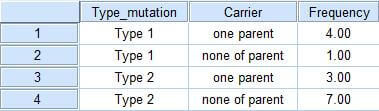
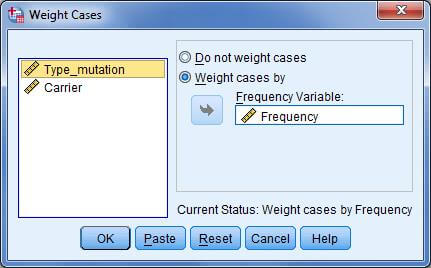
بعد از این کار مسیر Data > Weight Cases را طی کنید یا از نوار ابزار بر دکمه کلیک کنید و در کادر مکالمه مورد نظر متغیرFrequency را به عنوان متغیر وزنی تعریف کنید و گزینه ok را بزنید با این کار نرم افزار دیگر می داند که افراد با انحراف نوع ۱ که فقط یکی از والدینشان هم به این عارضه دچارند تعدادشان ۴نفر است!!
حالا می توانید دستور Crosstabs را اجرا کنید و خروجی به صورت زیر خواهد شد:
- مادامی که دستور Weight cases اجرا شده است داده ها به صورت وزنی هستند لذا برای خارج شدن از این حالت مسیر Data > Weight Cases را طی کنید و گزینه “Do not weight cases” را انتخاب کنید.
- وقتی داده ها وزن دارند در نوار وضعیت SPSS عبارت Weight on نوشته شده است.
- این دستور به خصوص زمانی کاربرد دارد که با داده هایی که سرو کار دارید که خام نیستند و تعداد آنها نیز زیاد است.
دستور Compute
بسیاری اوقات پیش می آید که محقق می خواهد عبارتی را به طور سطری و برای هریک از موردها (افراد) محاسبه کند برای مثال فرض کنید قد و وزن نمونه را داریم و می خواهیم برای هر فرد به طور جداگانه BMI یعنی قد و وزن را محاسبه کنیم. به عنوان مثالی دیگر فرض کنید در یک تست سنجش افسردگی که شامل ۱۵سوال ۵ گزینه ای (۱تا۵) است می خواهیم امتیاز افسردگی هر شخص را به طور جداگانه محاسبه کنیم ذر تمام این موارد دستور Compute می تواند به ما در محاسبه عبارت مورد نظر کمک کند.
برای بررسی این دستور ابتدا فایل داده “dietstudy” را از فایل های نمونه SPSS باز کنید.
میخواهیم میانگین وزن افراد در ۵ نوبت پیگیری (wgt0 تا wgt4)را محاسبه کنیم و در متغیری به نام mwgt در همین فایل داده ها محاسبه کنیم برای اجرای این دستور مسیر Transform >Compute variable را انتخاب کنید تا در کادر مکالمه Compute variable باز شود در کادر سمت چپ (Target variable) عبارت mwgt را تایپ کنید و در کادر سمت راست (Numeric expression) عبارت ۵/ (wgt0+wgt1+wgt2+wgt3+wgt4) را تایپ کنید برای این قسمت می توانید از صفحه کلید پایین یا گروه توابع (Function group) سمت راست هم استفاده کنید.
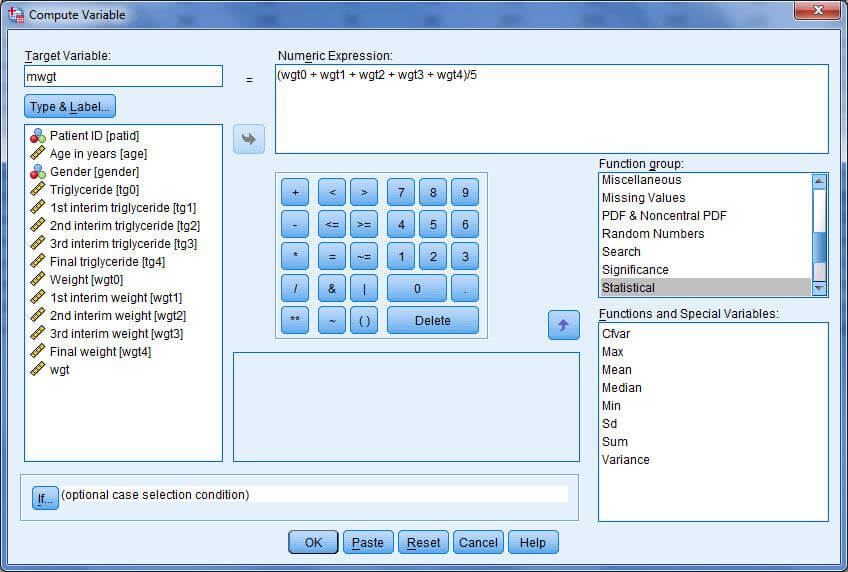
پس از اینکار کلید ok را کلیک کنید و به پنجره داده ها برگردید.خواهید دید که متغیری تحت عنوان mwgt به متغیرهای قبلی اضافه شده است که در واقع میانگین وزن هر فرد در ۵ دوره پیگیری است.
- در کادر مکالمه Compute variable با استفاده از تابع های موجود در قسمت Function group بسیاری از محاسبات آماری و ریاضی را می توان برای هر فرد به طور جداگانه انجام داد.
- این دستور به خصوص برای محققین رشته های پرستاری روانشناسی و علوم اجتماعی زمانی که با پرسشنامه سرو کار دارند کاربرد فراوانی دارد.
- فرض کنید بخواهیم برای گروهی از افراد نمونه یک فرمول و برای گروهی دیگر فرمولی دیگر را محاسبه کنیم در این حالت در کادر مکالمه Compute variable می توان از دستور if استفاده کرد.
دستور Count Values
یک تست سنجش افسردگی را در نظر بگیرید ممکن است محقق بخواهد بداند هر فرد در پاسخگویی چندبار گزینه ۳ را انتخاب کرده است برای پاسخ به این سوال باید از دستور Count values استفاده کرد
برای بررسی این دستور ابتدا فایل داده “tv-survey.sav” را از فایل های نمونه SPSS باز کنید.این فایل مربوط به یک نظر سنجی در مورد برنامه های تلوزیونی میباشد که شامل ۷ سوال بلی و خیر است. می خواهیم می خواهیم بدانیم هرفرد به طور کلی چند مرتبه به این سوالات جواب بلی (کد۱) را داده است وجواب را در متغیری تحت عنوان ny ذخیره کنیم
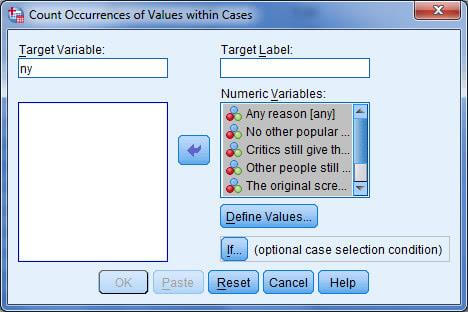
برای اجرای این دستور مسیر Transform>Count values را انتخاب کنید تا در کادر مکالمه count occurrence of values within cases باز شود در کادرسمت چپ(target variable) عبارت ny را تایپ کنید و در کادر variable همه متغیرهای سمت چپ (متغیرهایی که میخواهیم در آنها عدد ۱ خوانده شود) را وارد کنید.
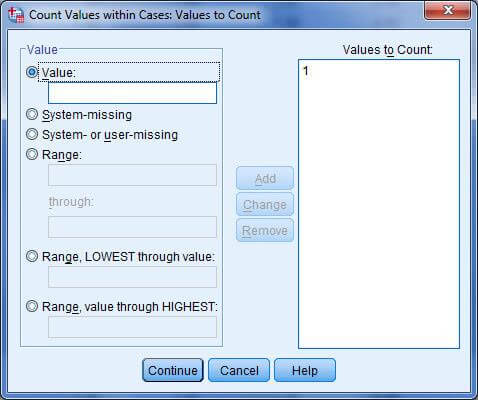
در این پنجره کلید Define values را کلیک کنید تا پنجره Count values within cases: values to count باز شود. در این پنجره انچه را که می خواهید شمارش شود را اضافه کنید در این مثال میخواهیم عدد ۱ شمارش شود.
لذا عدد ۱ را در قسمت values تایپ کرده و عبارت Add را کلیک می کنیم سپس دکمه Continue و ok را کلیک می کنیم. حال به پنجره داده ها برگردید خواهید دید که متغیری تحت عنوان ny به متغیرهای قبلی اضافه شده است که در واقع تعداد پاسخ های بله هر فرد است.
- در کادر مکالمه ای Count values within cases: values to count می توان نحوه شمارش را به صورت دیگری (غیر از مثال بالا) نیز تعریف کرد.همچنین می توان در این پنجره بیش از یک شرط شمارش تعریف کرد.
- هرگاه بخواهیم این شمارش را برای گروهی ازافراد نمونه با گروه دیگر از افراد نمونه متفاوت باشد باید از دستورif در کادر مکالمهCount occurrence of values within cases استفاده کرد.
دستور Recode
در این قسمت به بررسی دو کاربرد دستور Recode می پردازیم.
جدول فراوانی برای صفات کمی پیوسته (دستور Recode)
یک روش تعیین طبقات در فصل دوم ارائه شد.فرض کنید حدود طبقات را با این روش تعیین کردیم در این بخش میخواهیم این حدود طبقات را به نرم افزار معرفی کنیم تا داده ها را دسته بندی کند و به وسیله آن جدول فراوانی داده ها را رسم کنیم.
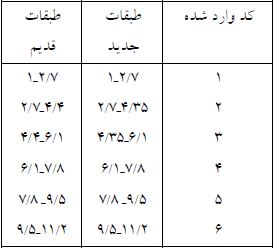
مثال) داده های مثال (تمرکز وزن در ۴۰ شهر بزرگ) را در SPSS وارد کنید و نام متغیر را O.C بگذارید. برای دسته بندی داده ها با استفاده از اس پی اس اس در گام اول حدود طبقات را به آن تعریف می کنیم و متغیر دسته بندی شده را به عنوان متغیری جدید در صفحه داده ها ایجاد می کنیم حدود طبقاتی که باید تعریف شوند به این صورت است.
توجه داشته باشید عدد ۴/۴ که یکی از کران هاست (کران بالای طبقه دوم و کران پایین طبقه سوم ) در داده ها نیز وجود دارد و از آنجایی که میخواهیم ۴/۴در طبقه سوم باشد در طبقه دوم و سوم بجای عدد ۴/۴ در کرانه ها عدد ۴.۳۵ را در نظر گرفته ایم و اگر اعداد ۲.۷، ۱.۶، ۷.۸ یا ۹.۵ نیز در داده ها بودند همین کار را انجام می دادیم.
برای دسته بندی داده ها مسیر Transform>Recode into different variables را انتخاب کنید تا در کادر مکالمه Recode into different variables باز شود. در این کادر متغیر”مقدار تمرکز وزن (O.C)” را انتخاب و وارد پنجره سمت راست (Numeric Variable->Output variable) می کنیم.
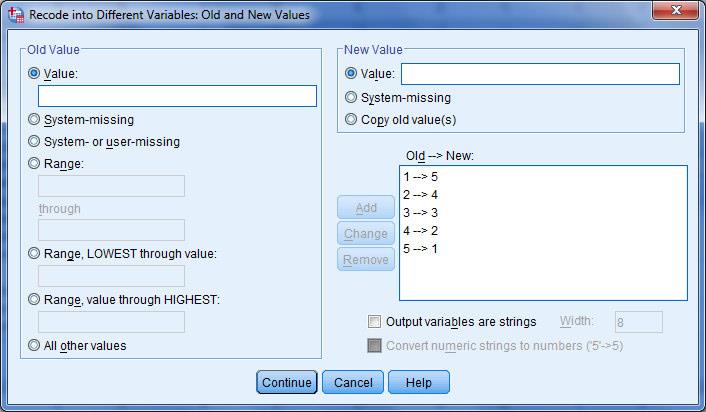
در قسمت سمت راست این کادر(Output Variable) و در قسمت Name نام متغیر جدید یعنی r_O.C راتایپ می کنیم و سپس دکمه Old and New values را کلیک می کنیم
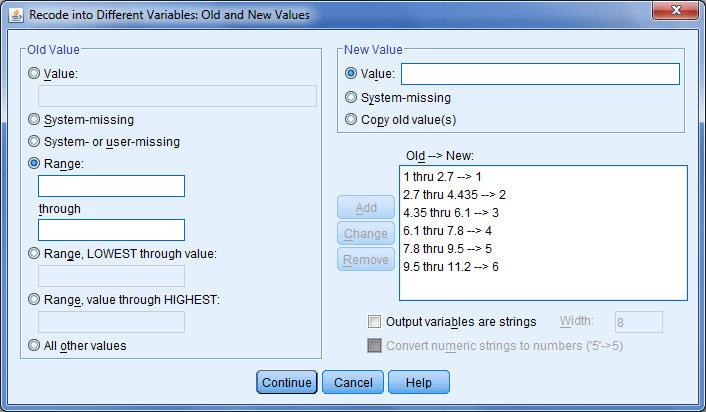
تا کادر Old and New values Recode into different variables: باز شود در این کادر و در قسمت Old values گزینه Range را انتخاب کنید و اعداد ۱ و ۲.۷ (حد بالا و پایین طبقه اول) را در این جعبه تایپ کنید در قسمت New values عدد ۱ را تایپ می کنیم و دکمه Add را می زنیم.
به همین ترتیب سایر طبقات را به نرم افزار معرفی می کنیم.
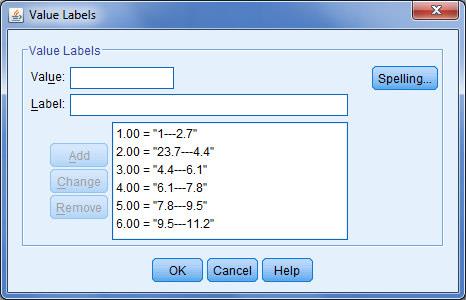
پس از اینکه معرفی طبقات به نرم افزار به اتمام رسید دکمه های Change. Continue و ok را به ترتیب کلیک می کنیم. حال به پنجره داده ها برگردید خواهید دید که متغیری تحت عنوان r_O.C به متغیرهای قبلی اضافه شده است که در واقع همان O.C است اما با کد بندی جدید.
گام دوم این است که به هر یک از طبقات متغیر جدید valueای در خور مانند شکل زیر در نظر بگیریم (در پنجره variable view) .
حال با استفاده از دستور Frequency برای متغیر r_O.C جدول فراوانی رسم کنیم.
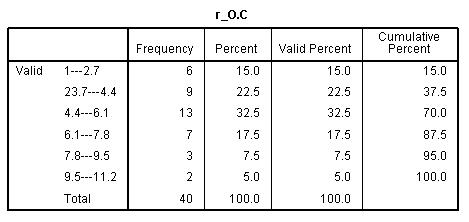
معکوس کردن امتیازات(دستور Recode)
همانطور که از نام این دستور پیداست توسط آن میتوان داده ها را دوباره کد بندی کرد. برای مثال فرض کنید در پرسشنامه ای ۲۰ سوالی ۱۸سوال با نمره گذاری ۱تا ۵ (مستقیم) معنی می دهد اما در ۲ سوال جهت نمره گذاری ۵ تا ۱ (معکوس)است. در این حالت بهتر است همه داده ها وارد شوند اما جهت نمره گذاری آن دو سوال را با استفاده از دستور Recode برعکس کرد.
برای بررسی این دستور ابتدا فایل داده “satisfy.sav” را از فایل های نمونه SPSS باز کنید می خواهیم کد بندی متغیر price را معکوس کرده و آن رت در متغیری جدید به نام r_price ذخیره کنیم برای این کار مسیر Transform>Recode into different variables را انتخاب کنید تا در کادر مکالمه Recode into different variables باز شود. در این کادر متغیر Price را انتخاب و وارد پنجره سمت راست می کنیم.
در قسمت سمت راست این کادر (Output Variable) و در قسمت Name نام متغیر جدید یعنی r_price را تایپ می کنیم و سپس دکمه Old and New values را کلیک می کنیم تا کادر Old and New values Recode into different variables: باز شود در این کادر در قسمت Old values عدد ۱ را در قسمت New values عدد ۵ را تایپ می کنیم و همین کار را برای کدهای ۴,۳,۲و۵ انجام می دهیم و آنها تبدیل به کدهای به ترتیب ۲.۳.۴و۱ می کنیم.
سپس دکمه های Continue.change و ok را به ترتیب کلیک می کنیم حال به پنجره داده ها برگردید. خواهید دید که متغیری تحت عنوان r_price به متغیرهای قبلی اضافه شده است که در واقع همان متغیر price است اما با کدبندی معکوس.

- کاربرد دیگر دستور Recode را بیشتر در فصل دوم در قسمت دسته بندی داده های کمی بحث کرده ایم.
- هرگاه بخواهیم دوباره کدبندی را برای گروهی از افراد نمونه با گروه دیگر از افراد نمونه متفاوت باشد در کادر مکالمه Recode into different variables باید از دستور if استفاده کرد.
- در منوی Transform دو نوع دستور Recode تعبیه شده است. یک نوع را در بالا بررسی کردیم حالت دیگر Recode into same . . . است که درآن متغیر جدیدی ایجاد نمی شود و اعداد دوباره کد بندی شده در همان متغیر اول ذخیره می شوند. لذا این امر باعث از بین رفتن اطلاعات اصلی می شود و استفاده از دستور Recode بدین گونه توصیه نمی شود.
امیدواریم از این مطلب در سایت صنایع سافت که درباره آموزش گام به گام اس پی اس اس بود، لذت برده باشید. هر سوال و نظری دارید برای ما کامنت بذارید، کمتر از یک روز پاسخ داده میشه 😉



سلام
مطلبتون خیلی مفید بود .
فقط محبت بفرمایید، این مطالب برای مهندس صنایعی که قراره در یک شرکت بزرگی استخدام شود کافیه؟ یا این که برای اس پی اس اس مطالب بیشتری هم هست؟
سلام تشکر
قطعا باید خودتون رو به روز نگه دارید